信息论_香农-费诺-埃利斯码编码
2020年12月8日下午10:39
2021年12月14日下午4:57
解压缩的程序都已经完成,程序为c语言。目前有一点点小bug(长文本的处理),但总体来说能用!
要求
实现香农-费诺-埃利斯对英文文本进行编码和解码
课设作业已经提交,所以我没什么功夫完善这个代码。代码内容仅作参考,交作业的话可以用一个简短的纯英语文本演示。长文本的压缩很大概率会出问题
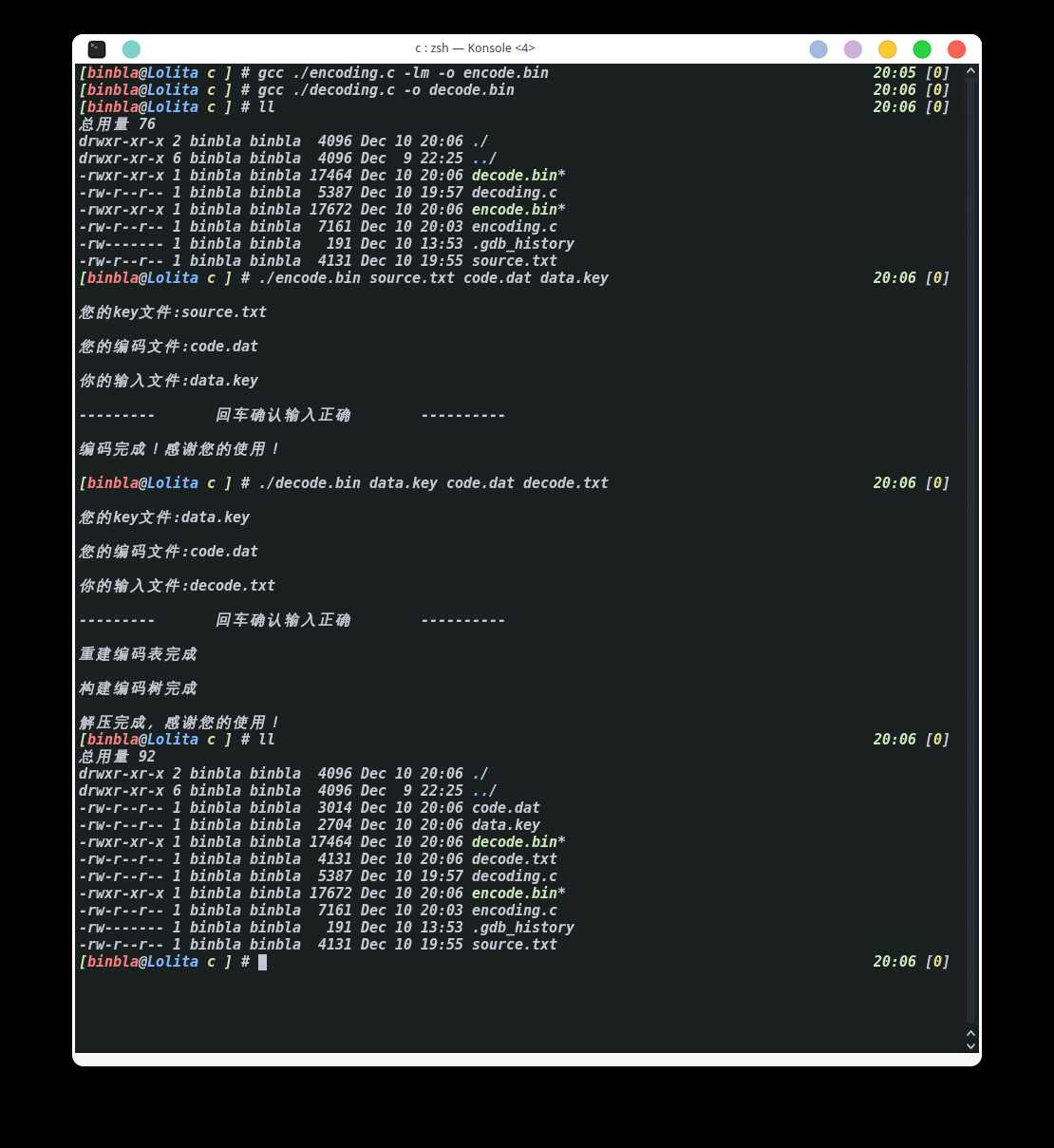
参考效果
- source.txt是需要编码的内容
- code.dat是编码后的二进制文件
- data.key是相对应的编码表
未实现的优化方案:这里可以更精简key文件,可以尝试使用四字节来描述二进制,用一个字节来描述码长。128*5=640字节。这样已经非常小了。
程序直接利用ascii表来做下标,可以实现只遍历一次就将整个文件计数完毕。
另外,修改了原有的码长计算公式,原来的公式似乎会重码。所以我在原本公式的基础上将码长多加了一个1;这样可以保证不会重码,压缩率变低了。(不知道是不是理解问题,参考的百度文库里的某一个文档)
必须保证文本里面的所有字符内容都是在ascii表能找到的。否则不能实现计数
代码
encode.c
/**
* @> Author : BinBla
* @> Date : 2020-12-07 18:38:49
* @> LastEditors : BinBla
* @> LastEditTime : 2020-12-10 20:03:26
* @> FilePath : /work/c/encoding.c
* @> Description : 压缩 输入文件 输出文件
* @> Gold : 实现香农-费诺-埃利斯码压缩
**/
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define CODE_MAX_SIZE 20 //编码大小(长文本需要很大,出现概率越小,编码越长)
#define TABLE_MAX_SIZE 128 //表大小
#define UNIT_SIZE 4096 //每次处理单位大小(过大会报错
typedef unsigned char uint8_t;
typedef unsigned short uint16_t;
typedef unsigned int uint32_t;
typedef unsigned long uint64_t;
typedef struct CodeTable {
char symbol; // 符号
long count; // 个数
double probability; // 概率
double cumProbability; // 累积概率
double fixCumulation; // 修正累积概率
uint8_t codeLen; // 码字长度
char codeWord[CODE_MAX_SIZE]; // 码字(临时使用字符数组存放伪二进制)
} codeTable;
typedef struct CodeKeyTable {
char symbol; //符号
char codeWord[CODE_MAX_SIZE]; //伪二进制
} codeKeyTable;
typedef struct KeyTable {
int unitsize; //读写单元大小,这个解码必须
long allSize;
codeKeyTable table[TABLE_MAX_SIZE]; //精简后的编码表
} keyTable;
void countChar(codeTable *table, char *buff, long size) {
int c = 0;
for (long i = 0; i < size; ++i) {
c = buff[i];
table[c].count += 1;
}
}
void printTable(codeTable *table) {
for (uint8_t i = 0; i < TABLE_MAX_SIZE; ++i) {
if (table[i].count != 0)
printf("%c\t%ld\t%lf\t%lf\t%lf\t%d\t%s\n", table[i].symbol,
table[i].count, table[i].probability, table[i].cumProbability,
table[i].fixCumulation, table[i].codeLen, table[i].codeWord);
}
}
void initTable(codeTable *table) {
for (uint8_t i = 0; i < TABLE_MAX_SIZE; ++i) {
table[i].symbol = i;
table[i].count = 0.0;
table[i].probability = 0.0;
table[i].cumProbability = 0.0;
table[i].fixCumulation = 0.0;
table[i].codeLen = 0;
}
}
void getBinaryList(char *dest, double tag, int allLen) {
int temp = 0;
for (int i = 0; i < CODE_MAX_SIZE; ++i) {
if (i < allLen) {
tag *= 2;
temp = tag; //强制类型转换
dest[i] = temp == 1 ? '1' : '0';
tag -= temp;
} else {
dest[i] = 0;
}
}
}
void finishCodeTable(codeTable *table, long size) {
double cum = 0;
for (uint8_t i = 0; i < TABLE_MAX_SIZE; ++i) {
if (table[i].count != 0) {
table[i].probability = ((double)(table[i].count) / size); // 获取概率
table[i].fixCumulation =
cum +
0.5 *
table[i]
.probability; // 获取修正累积概率(使用这个数据来构建二进制序列
cum += table[i].probability; // 累积当前概率
table[i].cumProbability = cum; // 获取累积概率(无用
table[i].codeLen =
(uint8_t)(log2(1 / table[i].probability) + 2); // 计算码长
getBinaryList(table[i].codeWord, table[i].fixCumulation,
table[i].codeLen);
}
}
}
void buildTableFinal(keyTable *key, codeTable *table, long allSize) {
key->unitsize = UNIT_SIZE;
key->allSize = allSize;
for (uint8_t i = 0; i < TABLE_MAX_SIZE; ++i) {
key->table[i].symbol = i;
strcpy(key->table[i].codeWord, table[i].codeWord);
}
}
void showTemp(char temp) {
putchar('\t');
for (int j = 0; j < 8; ++j) {
char c = (temp >> (7 - j)) & 1;
printf("%d", c);
}
// putchar('\n');
}
void writeDatOut(FILE *outFile, char *buff, long allLen, codeTable *table) {
uint8_t temp = 0; //以单个字节写入
char c; //当前压缩的字符(用作定位)
uint8_t last = sizeof(temp) * 8; //作为位运算的指针
uint8_t t;
for (long i = 0; i < allLen; ++i) {
c = buff[i];
for (uint8_t j = 0; j < table[c].codeLen; ++j) {
if (last == 0) {
fwrite(&temp, 1, 1, outFile);
last += 8;
temp ^= temp;
t = 0;
}
if (table[c].codeWord[j] == '1') {
temp |= 1 << (last - 1);
t = 1;
}
--last;
}
}
if (t) {
fwrite(&temp, 1, 1, outFile);
}
}
void preDeal(codeTable *table, long lastLen, FILE *in) {
char *buff = (char *)malloc(UNIT_SIZE);
long readLen;
while (lastLen > 0) {
if (lastLen > UNIT_SIZE) {
readLen = UNIT_SIZE;
lastLen -= UNIT_SIZE;
} else {
readLen = lastLen;
lastLen ^= lastLen;
}
fread(buff, readLen, 1, in);
countChar(table, buff, readLen);
}
}
void wirteDat(FILE *in, FILE *out, long lastLen, codeTable *table) {
char *buff = (char *)malloc(UNIT_SIZE);
int readLen;
while (lastLen > 0) {
if (lastLen > UNIT_SIZE) {
readLen = UNIT_SIZE;
lastLen -= UNIT_SIZE;
} else {
readLen = lastLen;
lastLen ^= lastLen;
}
fread(buff, readLen, 1, in);
writeDatOut(out, buff, readLen, table);
}
}
void printKey(keyTable *kTable) {
for (int i = 0; i < 128; ++i) {
if (kTable->table[i].codeWord[0] == '0' ||
kTable->table[i].codeWord[0] == '1')
printf("%c\t%s\n", kTable->table[i].symbol, kTable->table[i].codeWord);
}
}
int main(int argc, char *argv[]) {
char *buff; //临时数据
long allLen; //完整长度
long lastLen; //剩余需要录入的长度
long readLen; //即将录入的长度
if (argc != 4) {
printf(
"\n\tPz add file-true-path to the arg table!\n\n\tHear is an "
"example:\n\n\tencode.bin source.txt code.dat data.key\n\n");
return -1;
}
printf("\n您的key文件:%s\n\n您的编码文件:%s\n\n你的输入文件:%s\n\n", argv[1],
argv[2], argv[3]);
puts("---------\t回车确认输入正确\t----------");
getchar();
// 要求输入文本的输入路径(绝对路径相对路径均可)和压缩后的输出路径(绝对路径相对路径均可)
// 例如: ./encoding.bin ./inputFile.txt ./textCompress.dat ./dat.key
FILE *inputFile = fopen(argv[1], "r");
fseek(inputFile, 0, SEEK_END);
allLen = ftell(inputFile);
lastLen = allLen;
fseek(inputFile, 0, SEEK_SET);
codeTable *table = (codeTable *)malloc(sizeof(codeTable) * TABLE_MAX_SIZE);
initTable(table);
preDeal(table, allLen, inputFile);
finishCodeTable(table, allLen); //建立编码表
keyTable *kTable = (keyTable *)malloc(sizeof(keyTable));
buildTableFinal(kTable, table, allLen); //建立精简编码表(用于保存
// printTable(table);
//表构建完毕
//接下来再读一次文件开始编码压缩(这里可以优化,采用队列的方式实现文件只读一次)
FILE *outputFile = fopen(argv[2], "wb");
fseek(inputFile, 0, SEEK_SET);
wirteDat(inputFile, outputFile, allLen, table);
fclose(inputFile);
fclose(outputFile);
FILE *key = fopen(argv[3], "wb");
fwrite(kTable, sizeof(keyTable), 1, key);
fclose(key);
puts("编码完成!感谢您的使用!\n");
return 0;
}
decode.c
/**
* @> Author : BinBla
* @> Date : 2020-12-07 18:38:49
* @> LastEditors : BinBla
* @> LastEditTime : 2020-12-10 19:57:52
* @> FilePath : /work/c/decoding.c
* @> Description : 压缩 输入文件 输出文件
* @> Gold : 实现香农-费诺-埃利斯码解压
**/
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef unsigned char uint8_t;
typedef unsigned short uint16_t;
typedef unsigned int uint32_t;
typedef unsigned long uint64_t;
#define TABLE_MAX_SIZE 128 //表大小
#define CODE_MAX_SIZE 20
typedef struct CodeKeyTable {
char symbol; //符号
char codeWord[CODE_MAX_SIZE]; //伪二进制
} codeKeyTable;
typedef struct KeyTable {
int unitSize; //读写单元大小,这个解码必须
long allSize;
codeKeyTable table[TABLE_MAX_SIZE]; //精简后的编码表
} keyTable;
typedef struct Tree {
char *code;
struct Tree *left;
struct Tree *right;
} tree;
void initNode(tree *node) {
node->code = NULL;
node->left = NULL;
node->right = NULL;
}
void buildTree(tree *root, char *c, char *tag) {
switch (tag[0]) {
case '0': {
if (root->left == NULL) {
root->left = (tree *)malloc(sizeof(tree));
initNode(root->left);
}
buildTree(root->left, c, ++tag);
break;
}
case '1': {
if (root->right == NULL) {
root->right = (tree *)malloc(sizeof(tree));
initNode(root->right);
}
buildTree(root->right, c, ++tag);
break;
}
default: {
root->code = c;
break;
}
}
}
void printTable(keyTable *key) {
for (uint8_t i = 0; i < TABLE_MAX_SIZE; ++i) {
if (key->table[i].codeWord[0] == '0' || key->table[i].codeWord[0] == '1')
printf("%c,%s\n", key->table[i].symbol, key->table[i].codeWord);
}
}
void initTree(tree *root, keyTable *key) {
for (uint8_t i = 0; i < TABLE_MAX_SIZE; ++i) {
if (key->table[i].codeWord[0] == '0' || key->table[i].codeWord[0] == '1') {
// printf("获取到一个有效字符:%c\t%s\n", *(&key->table[i].symbol),
// key->table[i].codeWord);
buildTree(root, &(key->table[i].symbol),
key->table[i].codeWord); //递归构建当前字符的编码节点
}
}
}
void rebuildKeyTable(keyTable *key, FILE *keyFile) {
fread(key, sizeof(keyTable), 1, keyFile);
}
void showTemp(char temp) {
putchar('\t');
for (int j = 0; j < 8; ++j) {
char c = (temp >> (7 - j)) & 1;
printf("%d", c);
}
// putchar('\n');
}
void decompressUnit(FILE *out, FILE *in, tree *root, int size) {
char temp = 0; //操作空间
uint8_t tempLast = 8;
tree *treePointer;
char buff;
int z = 1;
int eof = feof(in);
while (size > 0) { //需要读取size数量的字符
treePointer = root;
while (1) { //读取一个字符
if (tempLast == 8 && eof == 0) { //获取一个字节新数据
fread(&temp, 1, 1, in);
eof = feof(in);
tempLast ^= tempLast;
}
if (temp < 0) { //高位1
if (treePointer->right == NULL) { //成功取出字符
// printf("成功取出字符:%c\n", *(treePointer->code));
// showTemp(temp);
if ((treePointer->code) == NULL) {
puts("一定是重码了!");
exit(-1);
}
buff = *(treePointer->code);
break;
}
treePointer = treePointer->right;
} else { //高位0
if (treePointer->left == NULL) { //成功取出字符
// printf("成功取出字符:%c\n", *(treePointer->code));
// showTemp(temp);
if ((treePointer->code) == NULL) {
puts("一定是重码了!");
exit(-1);
}
buff = *(treePointer->code);
break;
}
treePointer = treePointer->left;
}
temp = temp << 1;
++tempLast;
}
// printf("%c", buff);
fwrite(&buff, 1, 1, out);
--size;
}
}
void decompress(FILE *out, FILE *in, tree *root, long allSize, int unitSize) {
long lastSize = allSize;
int optionSize;
while (lastSize > 0) {
if (lastSize > unitSize) {
optionSize = unitSize;
lastSize -= unitSize;
} else {
optionSize = lastSize;
lastSize ^= lastSize;
}
decompressUnit(out, in, root, optionSize);
}
}
int main(int argc, char *argv[]) {
if (argc != 4) {
printf(
"\n\tPz add file-true-path to the arg table!\n\n\tHear is an "
"example:\n\n\tdecode.bin data.key code.dat decode.txt\n\n");
return -1;
}
FILE *keyFile = fopen(argv[1], "rb");
FILE *datFile = fopen(argv[2], "rb");
FILE *decodeFile = fopen(argv[3], "wb");
keyTable keyTable;
rebuildKeyTable(&keyTable, keyFile);
printf("\n您的key文件:%s\n\n您的编码文件:%s\n\n你的输入文件:%s\n\n", argv[1],
argv[2], argv[3]);
puts("---------\t回车确认输入正确\t----------");
getchar();
puts("重建编码表完成\n");
fclose(keyFile);
// printTable(&keyTable);
tree root = {NULL, NULL, NULL};
initTree(&root, &keyTable);
puts("构建编码树完成\n");
decompress(decodeFile, datFile, &root, keyTable.allSize, keyTable.unitSize);
printf("解压完成,感谢您的使用!\n");
fclose(datFile);
fclose(decodeFile);
return 0;
}
后记
这是一个非常新手的写法,代码质量很差,仅作训练参考

- b晴
- 【NOTE】树莓派4B使用archlinux aarch64 2024年2月1日
- 【饥荒DST】IPV6联机工具 2024年1月19日
- 【代码】阿里云DDNS python脚本 2023年11月7日
- 【NOTE】一加ColorOS 替换软件包安装管理器 2023年8月27日
- 一加AcePro刷氧OS 2022年9月8日
好像是会重码,每次decoding的时候会走到这个分支,请问可不可以改善一下这个问题?
这个编码公式给我的感觉就是字符多了肯定要重码。我在做这个的时候google了一圈,并没有看到这个编码的完整代码示例。所以我也不敢确定到底是不是这个编码方式的问题。所以很抱歉,这个问题我暂时解决不了。如果你只是做做密码学的课程设计的话,可以用短一点的ASCII文本敷衍一下,这个编码用得不多,意义不大。